
Find this post useful?
Share it around!
This is the second part of Percy Grunwald's series on Elixir. Don't miss out on the first article on Unicode matching in Elixir.
Exercises on Exercism are small, synthetic, and often seemingly trivial. It’s easy to imagine that experienced practitioners would have nothing to learn from them. However, solving these synthetic problems can push you to learn and apply parts of your language that you may not have explored. This new learning can lead you to solve real-world problems more efficiently or more expressively.
Parallel Letter Frequency is a medium difficulty exercise on Exercism's Elixir Track that unpacks a surprising number of interesting lessons. To solve this problem successfully your solution should execute in parallel in multiple worker processes. Achieving true parallelism in Elixir is surprisingly easy compared to other languages, but if you've never written concurrent code in Elixir, it may seem a little daunting. One of the things you'll discover in solving this exercise is how easy Elixir makes it to write code that can execute concurrently or in parallel. Applying these skills to your code can have a significant impact on the performance of your applications.
This exercise requires you to implement a function, Frequency.frequency/2, that determines the letter frequency in a list of strings. The calculation should be carried out in several worker processes, set by the workers argument:
iex> Frequency.frequency(["Freude", "schöner", "Götterfunken"], workers)
%{
"c" => 1,
"d" => 1,
"e" => 5,
...
"ö" => 2
}
In this post, we'll explore concurrency in Elixir by making a working sequential solution to this exercise concurrent. However, before we jump into the code, let's take a moment to examine what "concurrency" and "parallelism" actually mean, and how to achieve both in Elixir vs. other languages.
Concurrency and parallelism
Concurrency and parallelism are related terms but don't mean precisely the same thing. A concurrent program is one where multiple tasks can be "in progress," but at any single point in time, only one task is executing on the CPU (e.g., executing one task while another is waiting for IO such as reading or writing to the disk or a network). On the other hand, a parallel program is capable of executing multiple tasks at the same time on multiple CPU cores.
Both concurrent and parallel execution can give significant speed increases, but the amount of speedup possible -- if any -- is dependent on many factors. There are cases in which concurrency or parallelism are not even possible; it may be that the task you're trying to complete doesn't lend itself to either concurrent or parallel execution, or that the runtime doesn't support them. If your case does allow for concurrent or parallel execution, the amount of speedup possible is largely dependent on whether the task is IO- or CPU-bound, and whether there is more than 1 CPU core available.
Despite the number of contributing factors, there are a few "rules of thumb" for determining whether concurrency or parallelism is possible and how much speedup to expect. Firstly, concurrent execution is possible on a single CPU core, but parallel execution is not. Secondly, parallelism and concurrency should give significant speedup to IO-bound tasks, and the speedup should be nominally the same for both. Finally, CPU-bound tasks should have the same (or slower) performance when executed concurrently and generally speed increases are only possible when executed in parallel across multiple CPU cores.
The letter frequency calculation in this exercise is an example of a CPU-bound task, so according to rules of thumb above, a speed increase should only be possible by doing the calculation in parallel on multiple CPU cores.
Concurrency and parallelism in Elixir vs. other languages
Many popular languages give you tools to write concurrent code, but achieving parallelism is usually much more complex and full of trade-offs.
For example, concurrency is a first class citizen in JavaScript running on the Node.js runtime, and the default versions of IO-related functions are almost always "asynchronous" (i.e., concurrent). For example, fs.ReadFile is a concurrent function and the standard way to read the contents of a file. This is great but also has its downsides in the form of callback hell, or the need for Promises. Also, since Node doesn't schedule CPU time equally across tasks, it's still possible to block execution with a single CPU-intensive task. Parallelizing execution in Node is possible, but certainly not easy. Given that Node is single threaded, the only way to achieve parallelism is to manually fork worker processes with the cluster module or run multiple instances of your program and manually implement communication between them.
Python, unlike Node, is not concurrent by default but does give you multiple tools for writing concurrent and parallel code. However, each option has trade-offs and choosing one is not necessarily straightforward. You could use the threading module and deal with the fact that the global interpreter lock (GIL) limits execution to a single thread at a time, making parallelism impossible. The other option is Python's multiprocessing module, which bypasses the GIL limitation by spawning OS processes (as opposed to threads). Using multiprocessing makes parallelism possible but has the trade-off that OS processes are slower to spawn and use more memory than threads.
Writing concurrent and parallel code in Elixir is much simpler since Elixir is concurrent at the runtime level. Elixir's reputation for massive scalability comes from the fact that it runs on the BEAM virtual machine, which executes all code inside extremely lightweight "processes" that all run concurrently within the VM. BEAM processes have negligible cost to spawn and use minute amounts of memory compared to the OS-level threads and processes spawned by Python's concurrency modules. Also, in contrast to Node's event loop, the BEAM VM has schedulers that allocate available CPU time to all processes, which ensures that a single CPU-intensive task can't block other processes from executing.
Because of this architecture, going from executing processes concurrently to executing in parallel is just a matter of adding more CPU cores. In fact, for many years now BEAM automatically activates Symmetric Multiprocessing (SMP) capabilities on multi-core systems, which allows the VM's schedulers to allocate CPU time from all cores to the running processes. In Elixir, not only is concurrency a first class citizen, but there is no distinction between concurrent and parallel code. All you need to do is write concurrent code and the VM will automatically and by default parallelize it if there is more than 1 CPU core available.
Writing concurrent Elixir code with the Task module
As mentioned above, in Elixir, concurrency is achieved by distributing operations to multiple BEAM processes. You can very easily spawn processes with functions like Kernel.spawn_link/1, but you're much better off using the awesomely powerful abstractions provided by the Task module:
The most common use case for [Task] is to convert sequential code into concurrent code by computing a value asynchronously.
The Task module lets you write unbelievably clean concurrent code in Elixir -- no callback hell and no need for Promises.
For this exercise, Task.async_stream/3 is a great option:
async_stream(enumerable, function, options \\ [])
Task.async_stream/3 returns a stream that runs the given function concurrently on each item in enumerable. By default, the number of processes spawned (workers) is equal to the number of items in enumerable. This gives us a straightforward way to control the level of parallelism with the workers argument (assuming we have enough CPU cores). All we need to do is split the list of letters into the correct number of chunks and use Task.async_stream/3 to process each chunk in a separate worker.
Making the sequential letter frequency function concurrent
Let's start with a working sequential implementation from my solution:
def frequency(texts, _workers) do
texts
|> get_all_graphemes()
|> count_letters()
end
defp get_all_graphemes(texts) do
texts
|> Enum.join()
|> String.graphemes()
end
defp count_letters(graphemes) do
Enum.reduce(graphemes, %{}, fn grapheme, acc ->
if String.match?(grapheme, ~r/^\p{L}$/u) do
downcased_letter = String.downcase(grapheme)
Map.update(acc, downcased_letter, 1, fn count -> count + 1 end)
else
acc
end
end)
end
We can make the implementation above concurrent by doing the following:
- Split up the list of graphemes returned by
get_all_graphemes/1into a number of chunks equal to the number ofworkers - Process each chunk with
count_letters/1in a worker by usingTask.async_stream/3 - Merge the results from each worker into a single result
Here's a diagram of the steps above:
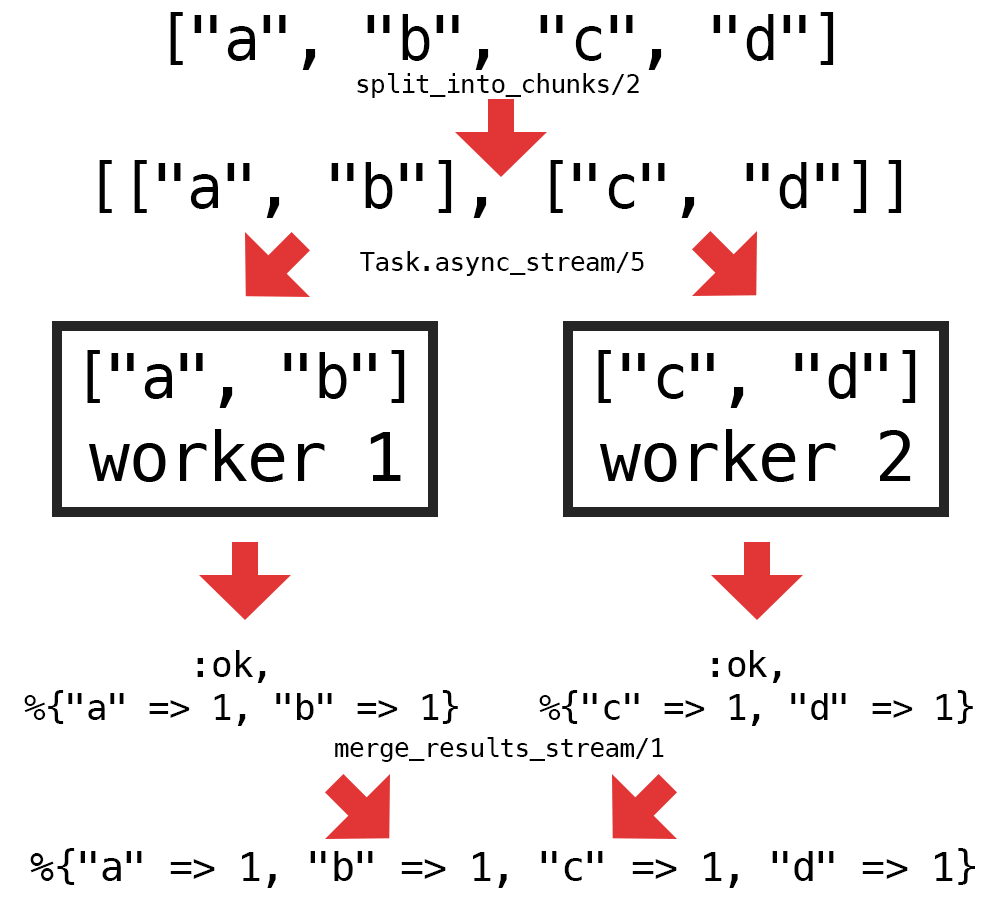
We only need to implement 2 new helper functions to enable the concurrent logic: one to split the graphemes into chunks (split_into_chunks/2) and one to merge the stream of results from the workers (merge_results/1). Here's one way to implement those helpers:
defp split_into_chunks(all_graphemes, num_chunks) do
all_graphemes_count = Enum.count(all_graphemes)
graphemes_per_chunk = :erlang.ceil(all_graphemes_count / num_chunks)
Enum.chunk_every(all_graphemes, graphemes_per_chunk)
end
defp merge_results_stream(results_stream) do
Enum.reduce(results_stream, %{}, fn {:ok, worker_result}, acc ->
Map.merge(acc, worker_result, fn _key, acc_val, worker_val ->
acc_val + worker_val
end)
end)
end
With those 2 functions implemented, all that's left to do to make the frequency/2 function run concurrently is to add calls to the new helper functions and replace the direct call to count_letters/1 with Task.async_stream/3:
def frequency(texts, workers) do
texts
|> get_all_graphemes()
|> split_into_chunks(workers)
|> Task.async_stream(&count_letters/1)
|> merge_results_stream()
end
The function above is a fully working concurrent implementation and passes all the tests. Despite being concurrent, the code reads exactly like regular sequential code, which demonstrates the power of the abstractions provided in Task.
Is the concurrent version actually parallel?
As I mentioned earlier in the post, there is no distinction between concurrent and parallel code in Elixir. If we set workers to a number greater than 1, and we have more than 1 CPU core available, the BEAM VM automatically parallelizes the execution of the spawned processes.
By default, BEAM starts a scheduler for each (logical) CPU core available. You can check the number of schedulers that BEAM has started with :erlang.system_info/1:
iex> :erlang.system_info(:schedulers_online)
8
This represents the maximum number of VM processes that can be executing at the same time. Setting workers to a number greater than the number of schedulers does not increase parallelism and may hurt performance.
Conclusion
Converting the code from sequential to concurrent turns out to be much easier than expected using Elixir's Task module. The concurrent code adds some extra complexity in the splitting of the list of graphemes and combining the worker results, but the end result is surprisingly clean.
Before solving this Exercism problem I had heard about Task, but never used it. After applying it in my solution, I would now consider it an indispensable part of my Elixir toolbox.
You could use this new tool in many ways to try to optimize performance in your applications. Most web applications are IO-bound and would, therefore, benefit from concurrency even if there is only a single CPU core available. One fairly reliable way to speed up a web application is to make HTTP requests concurrently:
def call_apis_async() do
["https://api.example.com/users/123", ...]
|> Task.async_stream(&HTTPoison.get/1)
|> Enum.into([], fn {:ok, res} -> res end)
end
The code above applies Task.async_stream/3 to call all the URLs in the list concurrently, as opposed to waiting for each request to complete before initiating the next, which should give a significant speedup depending on the duration of each request.
